Buongiorno, questa è la comunicazione del 15/04
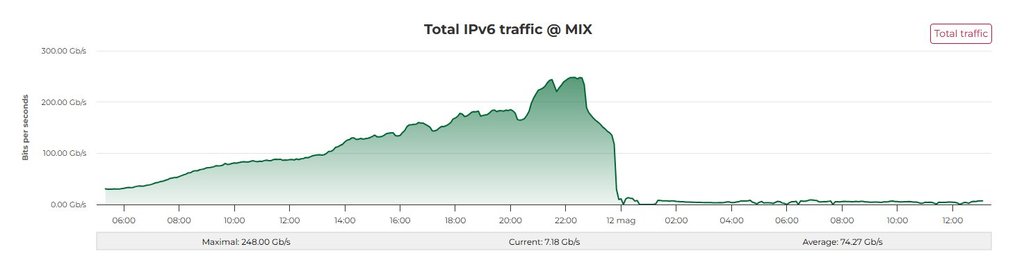
Il guasto di sta notte è identico a quello del 15/04, di seguito un riassunto di quello che è successo:
Dear Peers,
following RFO for this incident.
Around 01:00AM UTC+2 on Apr 15th we started recording some high CPU usage on vteps, this was due to traffic flooded from member port to the infrastructure which was causing control plane disruption.
Around 02:30AM UTC+2 thanks to friendly peers who we were communicating with us during the incident we discovered they were experiencing spotty connections, the prolonged high CPU usage caused mac table sync problems, after some brief investigation we decided to start forcing resync on all vteps which was completed around 03:20AM UTC+2.
At that time functionality was restored correctly but we were noticing vteps flooding a large amount of traffic to all interfaces.
After some extensive investigation we isolated a pair of multihoming devices causing the flood, restarted FRR and around 06:20AM UTC+2 the network was back to its fully operational state.
We developed a config change which will avoid the issue in the future. We're currently ending testing on the new features involved and will apply on infrastructure ASAP.
with my Best Regards,
Anche noi per ora abbiamo disattivato tutte le sessioni BGP sulla LAN di MIX